
用来转化html
课程介绍
大家好,我是帅地。
帅地剑指Offer刷题活动已经 组织了 6 次了,,不少跟着刷题的人,都收获巨大,比如这位二刷的同学

还有 一些社招工作了几年的同学,非科班转行的,基本算法 0 基础,没想到也能硬着头皮刷下去,虽然进度跟不上,但让我大受震撼


而且我看了下大家的打卡记录,没想到 50%+ 的人,都跟着打卡坚持了下来
现在无论是考研,还是面试,基本的都离不开算法题了,中大厂更是100%必考,所以帅地再次开始剑指Offer刷题,帮助大家拿下算法高频题。
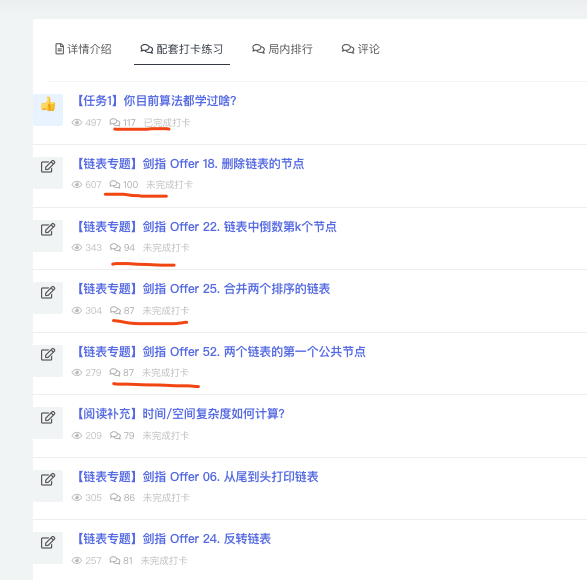
而且帅地不仅仅会带领大家刷题,还会不停让大家感受真题,比如对于链表专题,就给了好多面试真题
而且咱们的题目安排,并不是固定每天几道的,而是会根据题目的难易程度来安排的,比如有时 4 道,有时 2 道。

所以帅地在接下来,会常态化组织刷题打卡《剑指offer》,并且会不断优化刷题的安排。
为什么要刷剑指offer
这个我就不科普了,算法面试,已经成为必备了,而其中《剑指offer》里面的六七十道题,也成为了经典必刷题,里面六七十道题基本覆盖各类常见算法思想,所以学习《剑指offer》,更多还是学习一下解题思路 + 背后的算法思想,
《剑指offer》完整刷题攻略
不过说实话,虽然剑指offer这本书很经典,但是按照官方的顺序来刷题,可能我觉得不大适合初学者,并且我觉得,如果你时间不多,里面的一些题没有必要学,所以我会基于自己的理解,对内容重新进行规划安排。
大致的思路就是:我们按照专题来刷,并且由简到难来。并且帅地还会把自己之前面试遇到过的面试题也加上去。
并且我会对每一道题的重要性进行标注,这里大家还要明白一个事情,那就是我们的目的不是训练解题速度,而是掌握如何解决这道题,所以对于每一个分类的题,我会跟大家说一说这道题大致用到了什么方法,以及给大家找一找对应的文章学习。
总的来说,本系列不仅会带领大家刷题,还会进行的如下改装:
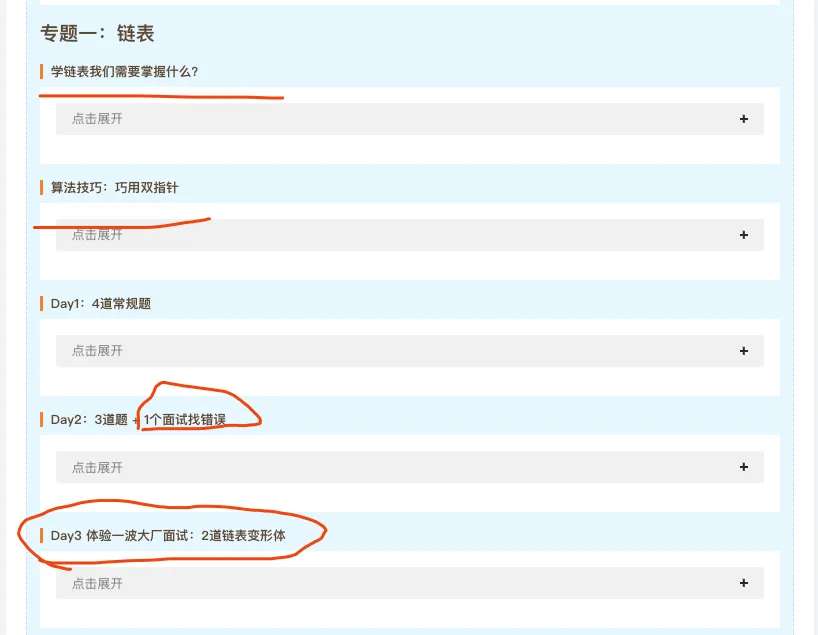
1、对《剑指offer》进行重新排序分类,让大家刷起来更加流畅,大概的分类如下

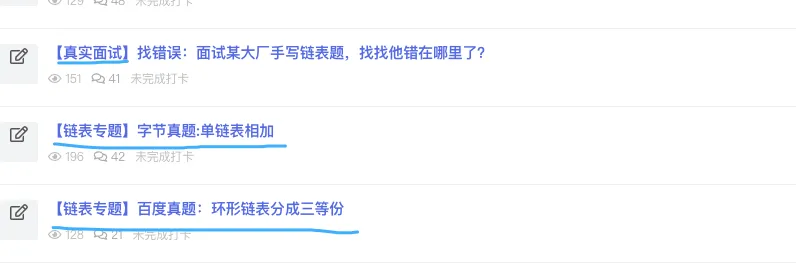
2、删除了部分我认为没必要学的题,新增了部分其他题,比如大厂面试题等等,同时还会提供入门文章,比如
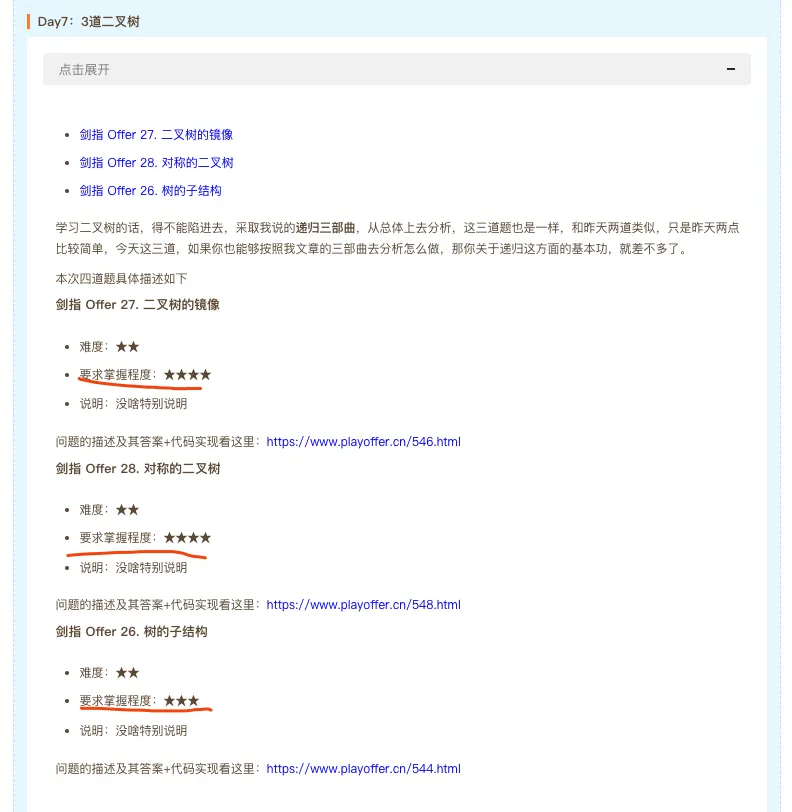
3、对每道题的重要程度进行的标记,方便大家有选择性学习,并且每道题提供视频版本答案,视频可以在帅地网站在线播放,答案手把手带大家写出答案
4、强行监督大家的打卡情况:你的每个打卡,都会被记录,你的坚持,大家也都看的见,比如
总之,相信通过这些安排,如果你认真跟着学,即使是初学者,也能对 算法题 有一个大致的框架,并且帅地每天给你安排题,你无需纠结进度。
适合用户
1、想要刷题更有针对性,急于准备算法面试的用户
2、想要学习算法,应付面试的用户
3、不清楚怎么安排算法学习进度的同学
4、想要学习算法的初学者
大致安排流程
有了6期的经验,并且视频题解已经录制好了,并且帅地的网站打卡机制也弄好了,每一期,都会更好。
0、时间安排:大概 35~40天为一期,总共 70+道题,其中有几天是休息。
1、帅地每天会给大致发布每日任务,并且会根据难易程度来安排每天的题量,而不是固定2道题,3道题,这样你们刷起来也顺手一些,另外就是一周 7 天,大概会休息一天,供大家追补上来。
2、每次发一个专题的时候,刷题会提供一些相关的文章供大家去入门,比如 并查集啊,动态规划啊,递归啊,二分啊,位运算啊,等等,这样可以让你有一个概念,之后配合练习+视频讲解,掌握大部分题型还是没问题的。
3、有完善的打卡机制,监督每个人的完成力度,成功打卡的同学,也会排名,最后排名高的同学能够获得大奖励哦
4、大家的水平都差不多,一起刷题,一起打卡,学习起来更加有气氛,有什么问题发群里,大家也能讨论,遇到实在不懂的,大家也能一起来解决你的问题。
关于题解
题解来自于我个人录制的视频,视频在 B 站是公开的,不过视频是按照顺序放在 B 站的,应该是 B 站目前把剑指offer讲的最详细的视频了。
所以呢,本次刷题主要给大家规划一下刷题顺序 + 进度,监督大家刷题,以及大家一起讨论,当然,刷题也会跟大家说一些刷题方法 + 给一些入门文章给大家学习。
语言:视频中是 Java 实现,网站中提供了 C++,Go,Python,JS等代码,不过帅地基本屏蔽了语言特性,其他语言基本也能看的懂,重点讲解思路。
费用 + 报名+开始时间
开始时间:没有固定时间,每次凑够 100 人就开车,预计2周内凑齐,大家可以先进群。
费用是:19.9 元。估计全网最便宜了
训练营学员:免费
如何报名?
下面购买后,即可看到隐藏内容:
此处内容需要权限查看